
vEADette est une application d’indexation automatique et d’audit des instruments de recherche en XML/EAD. Automatique car l’analyse et l’extraction sémantique emploie un LLM pour l’analyse de corpus d’instruments de recherche; et contrôlée car la génération des données repose sur l’emploi du vocabulaire fixé par les thésaurus réglementaires et les notices d’autorité permettant à la fois de se prémunir des hallucinations et de s’aligner sur les référentiels.
vEADette est conçu pour établir, à l’échelle d’un service d’archives, un rapport statistique afin de fournir des éléments statistiques sur les pratiques d’indexation et une indexation minimale des instruments de recherche au niveau haut.
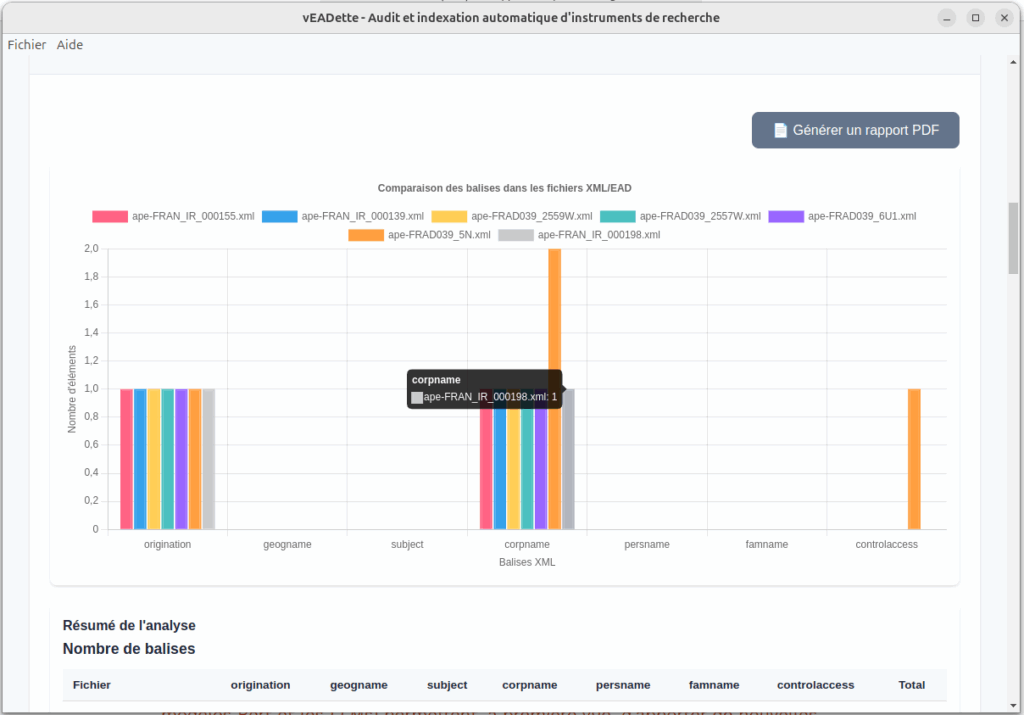
Il faut considérer cette application à la fois comme une manière d’expérimenter les méthodes récentes de génération ou sortie structurée par LLM pour les problématiques d’indexation; et de proposer une solution concrète d’indexation automatique de corpus d’instruments de recherche de taille moyenne. Les problématiques générales d’indexation seront exposées dans la partie 1) « Indexer des instruments de recherche »; une démonstration de l’outil en partie 2); une explicitation des méthodes et processus techniques mentionnés dans la partie 3) « Fondements techniques »; enfin 4) les pistes d’améliorations et 5) la note d’intention pour l’article de la Gazette des archives.
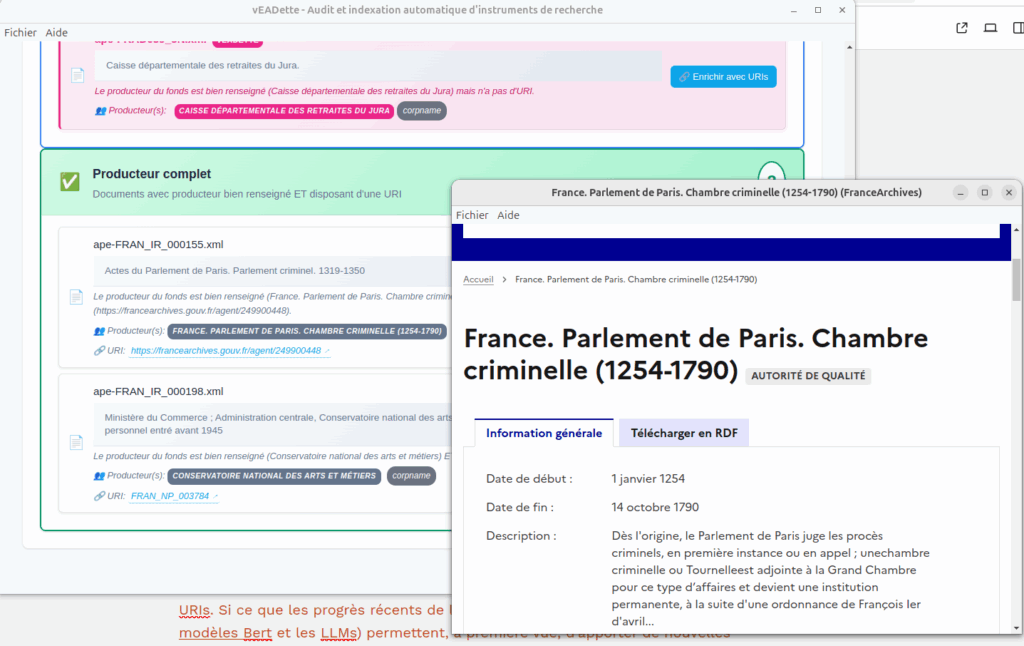
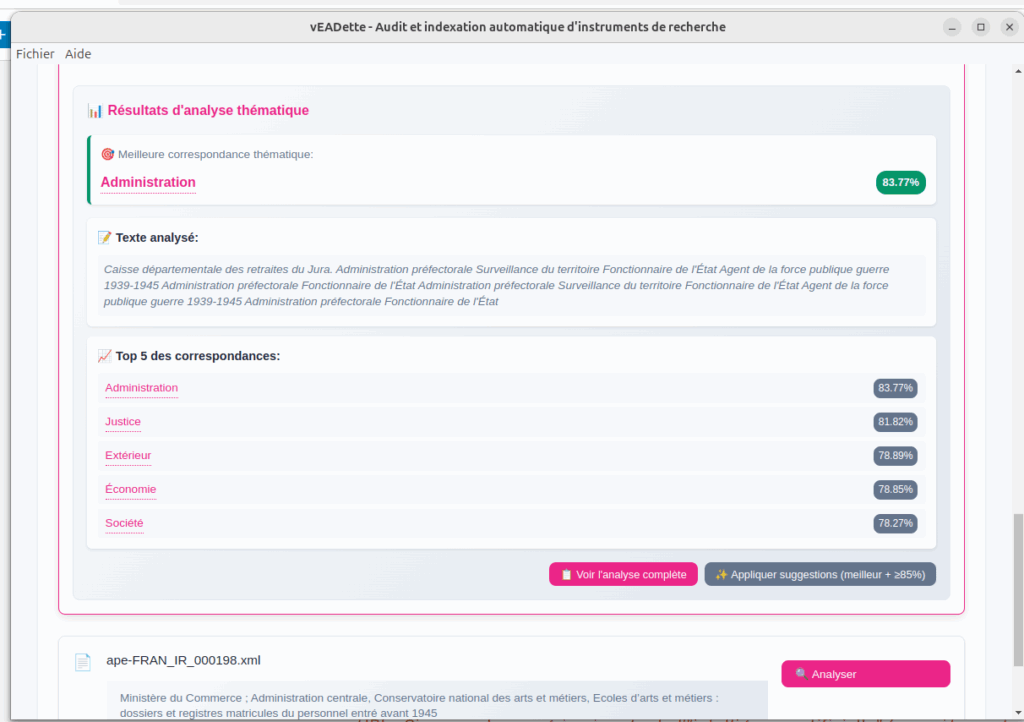
1. Problématique : indexer des instruments de recherche pour le web
L’indexation s’inscrit dans les enjeux de valorisation des fonds et ceux des nouvelles pratiques de recherche. Il est question de valorisation car une bonne indexation permet la « découvrabilité » des fonds d’archives — et donc de leur exposition au public –; et des « nouvelles pratiques de recherches » car la recherche documentaire n’implique plus seulement de fréquenter les instruments de recherche en salles de lecture, mais aussi de préparer sa visite en amont, par la recherche en ligne.
Il faut donc fournir, pour chaque instrument de recherche, des voies d’accès thématiques, géographiques ou bien nominatives (noms d’entreprises, personnes, familles, etc.). L’indexation est cette « condition préalable pour fournir un point d’accès sûr et vérifié à l’information en utilisant des notions clairement définies, représentées par des termes eux-mêmes soigneusement choisis et contrôlés » (Guide de l’indexation pour le web). Concrètement, cette indexation repose sur un ajout ou l’alignement des balises appropriées (origination, controlacess, subject, persname, corpname, famname, etc.) au regard des référentiels réglementaires publiés par le SIAF. Parmi ces référentiels, mentionnons le thésaurus matière, publié notamment sous format .rdf.
J’ai d’ailleurs implémenté ce thésaurus matière sous format de classes Python; mais aussi sous forme de représentations vectorielles pour la recherche sémantique. Voir ce projet annexe :
- Thes-ma-tic : https://github.com/desireesdata/Thes-mat-ic
Aux problématiques d’accès proprement dites, s’ajoutent celles, plus globales, des politiques d’indexation, exigeant une main d’œuvre et du temps pour reprendre les instruments de recherche. Mais cette reprise doit être fait à la lumière des thésaurus, des formes autorisées et la désambiguïsation des termes grâce aux URIs. Si ce que les progrès récents de l’ »intelligence artificielle » (concrètement : les modèles Bert et les LLMs) permettent, à première vue, d’apporter de nouvelles solutions pour indexer ou retoucher de façon industrielles des instruments de recherche, leur utilisation n’en reste pas moins sources de nouveaux problèmes techniques. Pour avoir une vue d’ensemble de ce qui est producteur de ces problèmes techniques (granularité disparate ou nulle des IR; balises mal utilisées), une phase d’audit est indispensable. C’est la raison pour laquelle vEADette a été pensé comme outil d’audit et d’indexation automatique, basé sur une utilisation particulière des LLMs. L’interface se veut simple pour se concentrer sur l’essentiel.
Parmi les outils sources d’inspiration, je mentionne évidemment Archifiltre.
2. Démonstration vidéo
3. Fondements techniques de l’indexation via la sortie structurée par LLM
L’application repose aussi bien sur des algorithmes basiques d’extraction de données (ReGex) que sur des approches plus modernes pour extraire le sens et le contexte des instruments de recherche, à savoir la sortie structurée via LLM.
La sortie structurée consiste ici à contraindre la génération de texte du LLM avec un nombre restreint de choix (ici implémentée en Python avec des classes Pydantic et le résultat d’extractions via Regex) et avec un format (JSON). Grâce à cette méthode, le LLM ne peut répondre: 1) qu’avec des champs imposés (par exemple les matières du thésaurus-matière); 2); faire des choix parmi des portions de texte qui lui auront été soumis. Cette méthode l’empêche le LLM d’halluciner — ce qui n’exclut pas la possibilité qu’il se trompe en catégorisant. Mais couplé aux embeddings, on peut recouper les résultats pour obtenir des valeurs pertinentes.
Il y a plusieurs façon d’extraire la sémantique de données : il y a les modèles Bert qui permettent, pour chaque token (ou mot) de les classifier selon une réserve « d’étiquettes ». Par exemple, cela permet de détecter le sujet ou le verbe d’une phrase; voire, selon le modèle choisi et s’il a été entraîné pour cela, détecter les métiers, les entités nommées. Cette approche qui consiste à « étiqueter » chaque mot, à peu à la façon d’un balisage, requiert une phase d’entraînement qui peut reporter leur mise en application concrète pour répondre à des besoins particuliers — par exemple ceux de l’archiviste. Cette approche n’a pas été choisie ; mais pourra t-être employée ultérieurement pour renforcer le contrôle des données.
L’utilisation d’un LLM (Mistral 8b) que l’on peut employer via des APIs (grosso-modo des services mis à disposition via internet) a été l’option choisie car les modèles mis à disposition sont suffisamment performants pour se passer d’une phase d’entraînement. Ils sont prêts à être utilisés.
Dans vEADette, la sortie structurée est employée pour la détection du producteur de thématiques, des entités géographiques, des institutions.
vEADette repose aussi sur des méthodes plus classiques d’embeddings pour la détection des thématiques et l’attribution des fiches d’autorité au regard du producteur du fonds. Cela consiste à « vectoriser » la sémantique des mots et de calculer entre eux leur proximité. L’ensemble des notices d’autorités des producteurs de France Archives ont été récupérées via SPARQL puis vectorisées. vEADette embarque donc une base de donnée vectorielle pour effectuer des recherches.
4. Améliorations
L’application a été développée en peu de temps; un travail sur le plus long terme permettrait de consolider les processus d’analyse; l’interface utilisateur; et d’établir une indexation fine sur l’ensemble des entités indexables, au regard d’une politique d’indexation choisie. Des fonctionnalités, plus orientées sur la normalisation/alignement des IR sur un modèle générique sont aussi envisagées. L’accent a été mis sur la détection du producteur du fonds, car connaître cette information permet de contraindre plus efficacement et d’affiner l’indexation à un niveau plus fin si on en connaît la nature de l’activité.
Il pourrait être intéressant, côté attribution des URI, de sélectionner des entités avec des autorités provenant de la BnF, Wikidata ou VIAF, en plus de France Archives.
Il pourrait être intéressant de proposer également la génération de fiches EAC à partir de la notice producteur le plus proche.
Enfin, il pourrait être intéressant de se reposer sur des plus petits modèles, spécialisés; et d’employer un contrôle encore plus stricts en contrôlant directement les probabilités de chaque mot généré par un LLM (logits) en lui imposant par exemple des graphes.
5. Note d’intention
L’article lié à ce projet porterait donc sur l’emploi de la sortie/génération structurée à des fins archivistiques, tels que présentées ici de façon synthétique et utilisés par un cas concret, ici l’application vEADette. Il sera question des forces et des faiblesses de la génération structurée; du double avantage de la contrainte par des thésaurus (empêche à la fois les hallucinations et aligne les instruments de recherche sur les référentiels réglementaires).
A noter que ce travail a été fait en marge de mon stage de fin d’études pour le projet Mezanno (BnF / EPITA / IGN / EHESS) où je travaille sur l’évaluation de la génération structurée des LLMs et sur des métriques d’évaluation (avec, comme cas d’étude, l’extraction de l’activité des sénateurs de la IIIe République via le Journal Officiel).
Bibliographie
- France Archives. Guide d’indexation à l’heure du web, 2021.
- Géraldine Geoffroy,
- Comment apprendre l’EAD à un LLM? https://iaetbibliotheques.fr/2024/11/comment-apprendre-lead-a-un-llm, 2024.
- Extraction de données structurées avec des LLMs, https://iaetbibliotheques.fr/2024/10/extraction-de-donnees-structurees-avec-des-llms, 2024.
- cmonnier. « Construire des points d’accès unifiés vers les archives : l’expérience FranceArchives ». Billet. Modernisation et archives (blog), 10 janvier 2020. https://doi.org/10.58079/u5yd.
- Naud, Dominique. « Réutiliser les données ouvertes afin d’obtenir une vue d’ensemble des ressources disponibles sur le portail FranceArchives ». Billet. Modernisation et archives (blog), 19 mars 2025. https://doi.org/10.58079/13ils.