J’ai conclu la dernière vidéo avec une commande qui a permis d’obtenir, dans un fichier txt, la transcription d’une image. C’était l’occasion de vérifier à la fois que kraken et nos modèles étaient bien installés et utilisables. Dans cette deuxième vidéo, nous allons voir l’anatomie d’une ligne de commande kraken et, pour ce faire, connaître le paysage global des processus sous-jacent à l’OCR ou HTR. Car à chaque chaque partie de la commande, représentées ici par une couleur, correspond, un processus (et des entrées/sorties).
Lien du programme en js pour la visualisation des données issues de la segmentation : https://editor.p5js.org/desireesdata/sketches/Hh7hflOZv
Voir la partie 1 : https://desireesdata.fr/tutoriel-prise-en-main-de-kraken-episode-1/
Documentation kraken
kraken --help
# Doc relative aux sous commandes :
kraken segment --help
kraken ocr --helpEntrées, sorties
L’enjeu principal d’un projet d’OCR est d’extraire d’une ou plusieurs images (ce sont les entrées) du texte (c’est notre sortie). Et si possible du texte structuré et enregistré dans un fichier que l’on pourra utiliser pour tel ou tel usage: ainsi, au lieu d’avoir une sortie brute au format txt, on pourrait générer un format XML.

On ne va donc s’intéresser qu’aux trois derniers blocs, de l’image à la sortie, par exemple XML avec la grammaire ALTO (on a vu dans l’épisode précédent qu’on pouvait faire une sortie du texte en brut, au format txt). Les inputs, impliquant une sortie, sont déclarés avec -i. Les inputs/outputs fonctionnent donc par paires.
kraken -i input.jpg output.jpg [...]
kraken -i input1.jpg intput2.jpg output1.txt output2.txt [...]On peut aller plus loin, par exemple sélectionner plusieurs images dans un dossier. Mais à ce niveau, je me suis contenter d’expliquer la logique sur une seule paire d’entrée/sortie.
Cette image, qui vient du site de Kraken, montre les aspects techniques sous-jacents (sur le site le texte souligné est cliquable et ramène vers la documentation associée) :
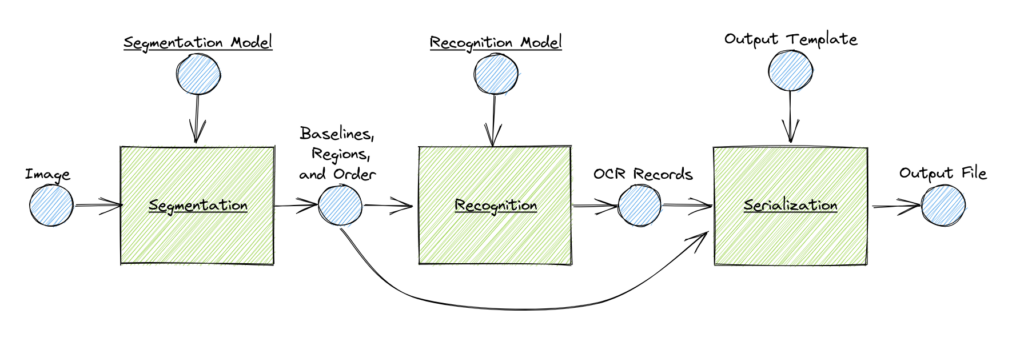
- la segmentation :
- définit les zones de la page, du général au particulier: page, bloc de texte, zone des lignes de texte, ligne de bases du texte
- ce sont des informations spatiales, en pixels, exprimées sous forme de coordonnées cartésiennes (x, y)
- la reconnaissance de caractères proprement dite (OCR)
- -m pour préciser le chemin du modèle employé
- retourne du texte et des informations spatiales pour chaque « glyphe » (lettre)
- la sérialisation
- agrège les données spatiales de la segmentation et de l’ocr
- la façon dont les données sont agrégées dépend du template choisi, passé en paramètre au début (-a pour une injection des données dans un template xml/alto).
On pourrait en fait ajouter une autre étape, préliminaire à toute celles là : le preprocessing qui consiste à avoir des images exploitables pour avoir de meilleurs résultats.
Ainsi, chaque partie d’une commande kraken renvoie à un processus, ou à des inputs/outputs à passer en paramètres. Par exemple, la partie rouge (« segment -bl ») renvoie au processus de segmentation. Si on ne précise pas de modèles de segmentation en entrée, c’est blla.model qui est choisi avec -bl (pour le modèle « baseline segmenter »).
On peut aussi modifier le sens de lecture avec d’autres options pour les textes en hébreu ou en chinois par exemple, avec -d horizontal-rl (r = right, l = left) pour une écriture horizontale de droite à gauche; ou encore -d vertical-lr pour le chinois.
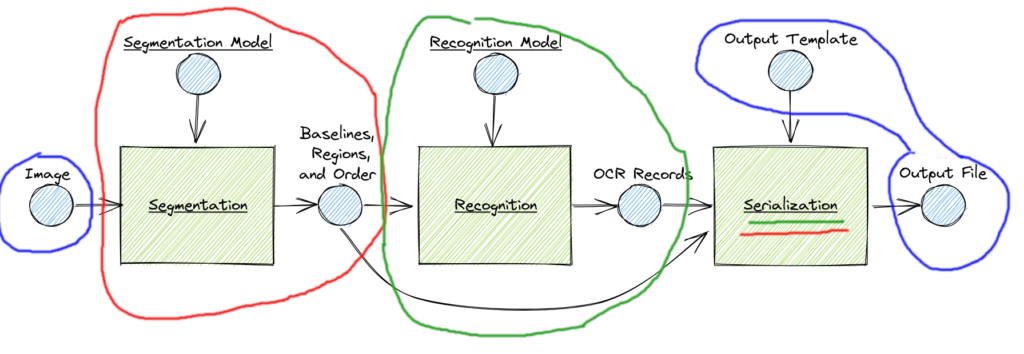

La partie verte (ocr -m nom_du-modele.mlmodl) renvoie au processus de reconnaissance de caractère proprement dite.
La sérialisation est implicite et dépend du template choisi en option à l’entame de la commande kraken, avec par exemple -a.
Dans la prochaine vidéo, je m’attarderai sur les fichiers de sortie et la visualisation des données générées par kraken.
2 réponses à “Tutoriel : prise en main de Kraken, épisode 2 (anatomie d’une ligne de commande).”
Bonjour,
Je viens de tomber sur ton blog qui m’a permit d’avancer sur l’utilisation de Kraken OCr. Je débute dans recherche en généalogie et mon projet donc est de pouvoir faire des scripts, pour analyser des documents type .png et de pouvoir retrouver des infos dans des registres manuscrits, je souhaite pouvoir créer un script qui les fichiers (en manuscrit). png en fichier text pour effectuer cette recherche. J’attends avec impatience ta 3ème vidéo.
Merci
Bonjour jacky, merci pour ton commentaire. Je n’ai pas abandonné la série : il me faut trouver un peu de temps pour faire la troisième vidéo ! Peut-être la semaine prochaine, ou dans une dizaine de jours. J’espère qu’elle pourra t’aider pour tes projets ! Une bonne journée